Voice conversion is a challenging task which transformsvoice characteristics of a source speaker to a target speakerwithout changing linguistic content. Recently, there havebeen many works on many-to-many Voice Conversion (VC)based on Variational Autoencoder (VAEs) achieving goodresults , however, these methods lack the ability to disen-tangle speaker identity and linguistic content to achieve wellgeneralized performance. In this paper, we propose a new method based on feature disentanglement to tackle many-to-many VC. By capability of disentangling speaker identityand linguistic content from utterances, Disentangle-VAE canconvert from many source speakers to many target speakerswith a single autoencoder network. Moreover, it achieves well generalized performance with unseen target speakers. We perform both objective and subjective evaluation to verifythat our proposed method is able to transform source utterances to target utterance with high audio naturalness andtarget speaker similarity.
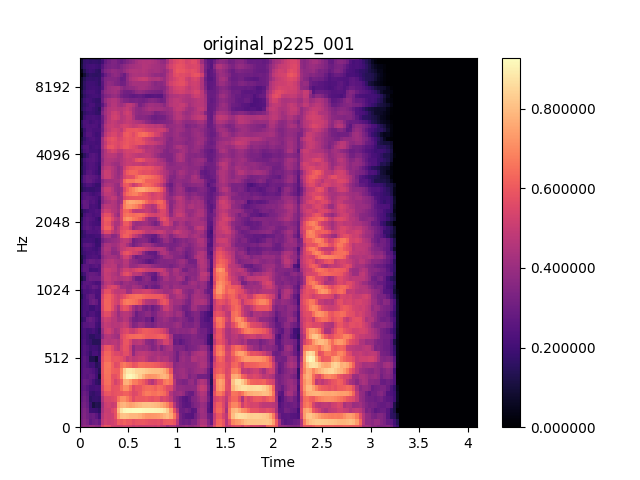
Melspectrogram Visualization
We conducted experiments on melspectrograms feature and relized that the speaker embedding has significant impact to melspectrograms. This phenomenon
explains for our assumption which is there are some common factors represent speaker identity embedded in speaker embedding, the other distinct factors represent linguishtic content extracted in content latent vector. Hence, by swapping speaker embedding between two utterance Disentangle-VAE is able to transform the identity of source speaker to the identity of target speaker.